
證券時報·e公司
2025-03-22 07:48


繼快思考模型Turbo S后,騰訊又推出了自研深度思考模型混元T1正式版。據介紹,這是一款“能秒回”的強推理模型,也是工業界首次將混合Mamba架構無損應用于超大型推理模型。
3月21日深夜,騰訊混元大模型團隊正式推出了自研深度思考模型混元T1正式版。該模型具有效果好、速度快的特點,多項指標達到業界領先推理水平,吐字速度達到每秒60—80tokens,在實際生成效果表現中遠快于DeepSeek-R1推理模型。

能秒回的深度思考模型
目前,用戶在使用DeepSeek-R1等推理模型時,由于模型需要進行深度思考,并在提供回答前列出詳細的思維鏈,雖然能夠體現較高的智能化水平,但存在響應速度慢、不夠高效的短板。
混元T1正式版則致力于解決這一問題,不僅吐字快、能秒回,還擅長超長文處理。在體現推理模型基礎能力的常見基準測試上,如大語言模型評估增強數據集MMLU-PRO中,混元T1取得87.2分,超越了DeepSeek-R1,僅次于o1。
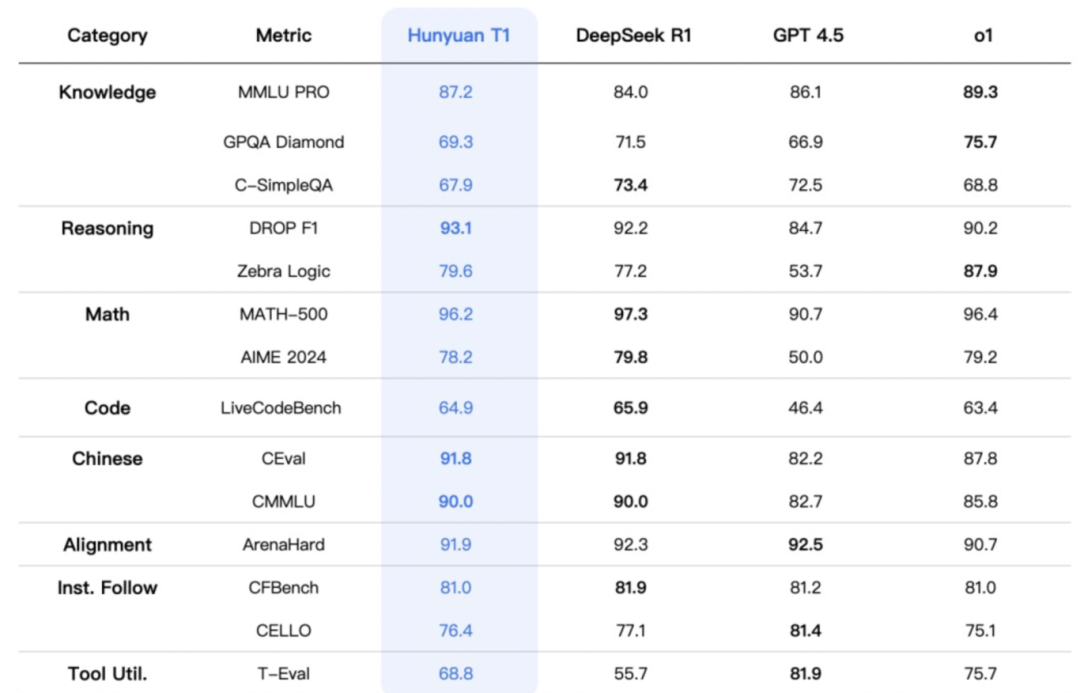
值得注意的是,混元T1正式版沿用了混元TurboS的創新架構,采用Hybrid-Mamba-Transformer融合模式。這一架構有效降低了傳統Transformer結構的計算復雜度,減少了KV-Cache的內存占用,從而顯著降低了訓練和推理成本。
這也意味著,騰訊摒棄了傳統及主流的純Transformer架構,首次將混合Mamba架構無損應用于超大型推理模型。
目前,混元T1已在騰訊云官網上線。價格方面,輸入價格為1元/每百萬tokens,輸出價格為4元/每百萬tokens,輸出價格為DeepSeek標準時段的1/4,與DeepSeek優惠時段一致。
騰訊大模型業務動作頻頻
作為大模型的“后發者”,騰旭今年以來動作頻頻,不僅快速地將旗下十余款產品接入了DeepSeek,自研的混元模型系列也進入快速迭代期。同時,騰訊也在加大對C端產品元寶的投入,積極搶占大模型用戶入口。
騰訊3月19日發布的最新財報顯示,騰訊2024年全年實現營收6603億元,同比增長8%;凈利潤為1940.7億元,比上年增長68%。騰訊董事會主席兼首席執行官馬化騰在業績會上表示,在過去一兩個月里,AI得到了很大發展,尤其是在DeepSeek橫空出世后,騰訊在云業務、“元寶”(AI應用)上都積極擁抱DeepSeek。
據騰訊官方微信號發布,自今年2月來,騰訊元寶接入DeepSeek滿血版和全新混元模型,雙核驅動元寶高速進化、日更級迭代,35天版本已經更新30次。除此以外,目前騰訊已有元寶、微信、騰訊文檔、QQ瀏覽器、QQ音樂、微信讀書等數十款產品及業務接入DeepSeek。
業內人士分析,作為擁有強大生態和用戶基礎的公司,騰訊如今通過走混元模型+DeepSeek模型結合的路徑,致力于在AI應用領域構建起自身的競爭優勢。
馬化騰在業績會上還表示:“數月前,我們重組了AI團隊以聚焦于快速的產品創新及深度的模型研發,增加了AI相關的資本開支,并加大了我們對原生AI產品的研發和營銷力度。我們相信這些增加的投資,會通過提升廣告業務的效率及游戲的生命周期而帶來持續的回報,并隨著我們個人AI應用的加速普及和更多企業采用我們的AI服務,創造更長遠的價值。”
財報顯示,2024年第四季度,騰訊資本開支同比增長386%至365.8億元,2024年全年資本開支達到767.6億元,同比增長221%,創歷史新高,占總營收的11.6%。研發投入方面,2024年全年的AI研發投入達到706.9億元,2018年至今累計投入3403億元。騰訊總裁劉熾平表示,第四季度的資本支出增加非常顯著,這是由于這一季度公司購買了更多GPU以滿足推理需求,計劃在2025年進一步增加資本支出。
責編:李丹
校對:彭其華

(點擊圖片進入報名頁面)






